The GraphQL Dataloader Cookbook
Dataloaders are the unsung heroes of GraphQL. They batch requests together to reduce hits to the database (DB). They cache the results in-memory to eliminate requests altogether. They solve the dreaded n + 1 problem that plagues REST and naive GraphQL implementations.
At Parabol, we’ve been using dataloaders for almost 6 years. Along the way, we’ve invented some pretty neat patterns to use them for standard DB requests, Authenticated REST endpoints, external GraphQL endpoints, GraphQL subscriptions, and more.
What is a Dataloader?
A dataloader is simply a batching algorithm paired with an in-memory cache. Imagine a request is received for 5 tasks and the 5 owners of each of those tasks. Using a naive approach, each task would be individually queried from the database. Then, after each task was returned, the 5 owners of each task would be queried from the database, totaling 10 database hits.
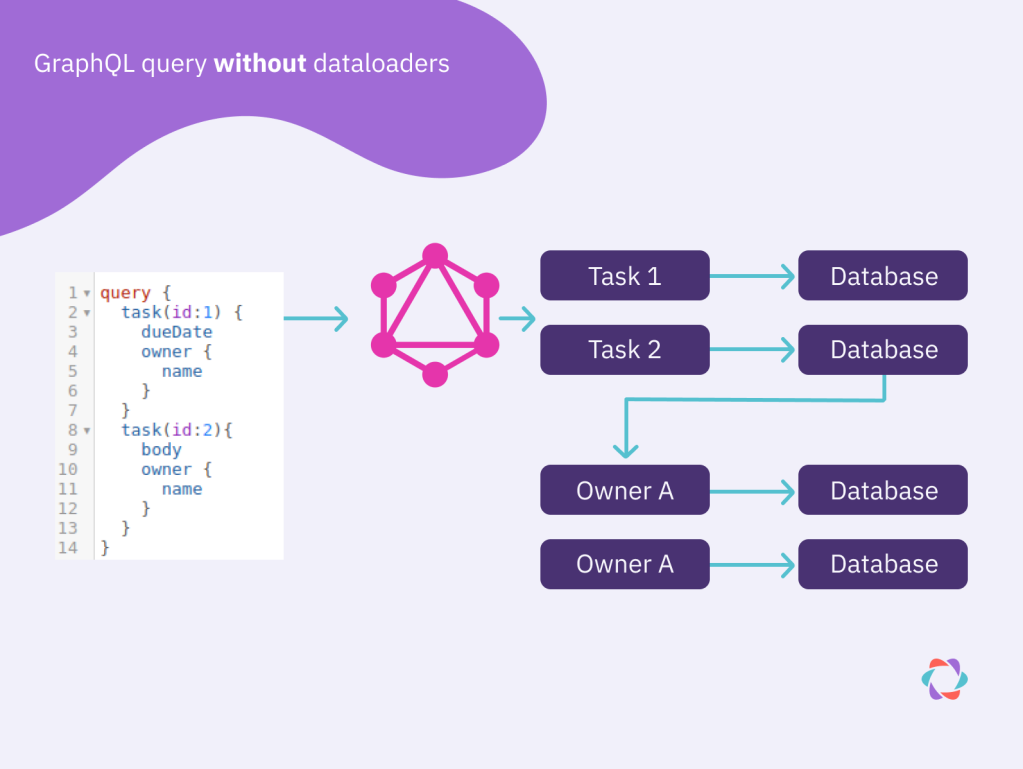
A dataloader optimizes this problem by first batching all the task queries so instead of 5 individual requests, it only makes 1 request with 5 IDs. By default, items that are queried on the same “tick” are put into the same batch and run as soon as the event loop is free, which is generally in less than 1ms.
The in-memory cache works by caching the requested ID. That means if those 5 issues all have the same owner, then only a single request for a single ID is sent to the database. Even better, if that owner was previously fetched (for example, from another part of the query), then a dataloader returns a promise that resolves immediately to the cached user.
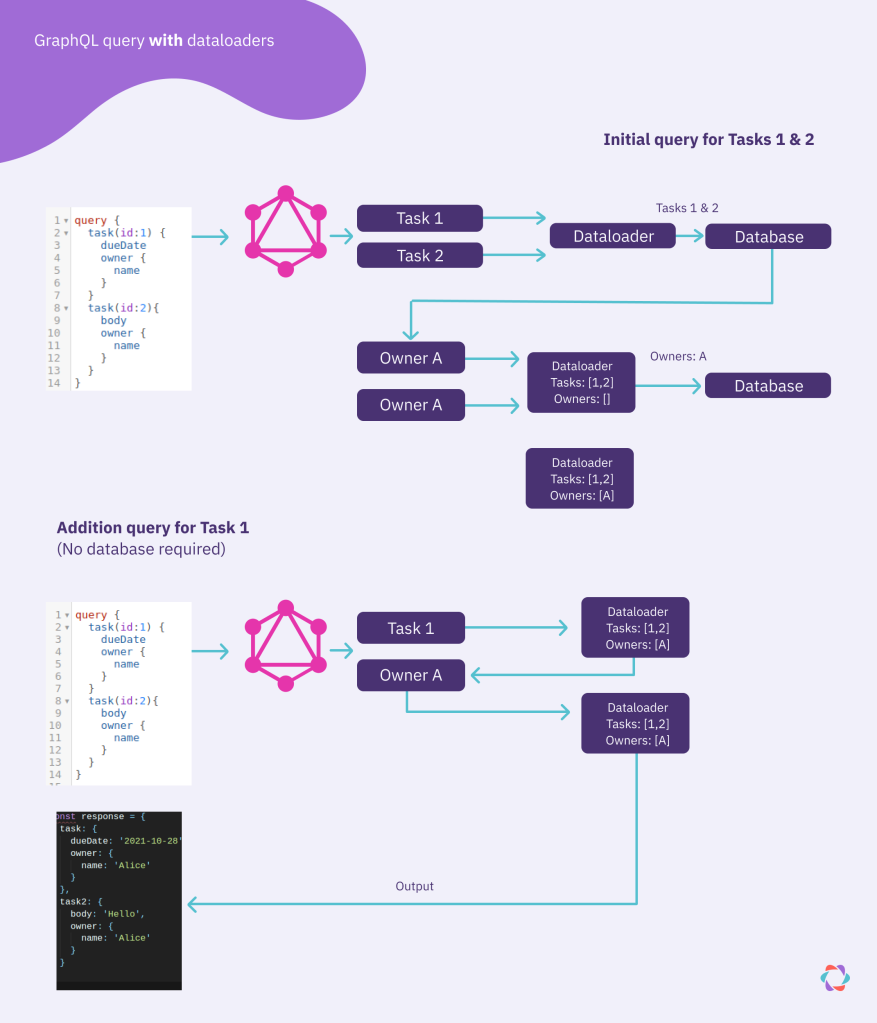
In practice, it’s common for a GraphQL query to contain graphical data. For example, requesting a single user, all the tasks for that user, and the owner of each of those tasks. By caching these responses as the graph is traversed, it’s guaranteed that a single request never queries the database for the same information twice. The developer is only responsible for determining how the dataloader communicates with the data source.
Recipe #1: SQL Database and Foreign Keys
At Parabol we love Postgresql. Nothing beats the performance and flexibility that a raw SQL query can offer. That means we don’t use ORMs, query builders, or extra layers of abstraction. Each query we write lives in its own .sql file. To make those queries play nicely with dataloaders, we simply change the query to accept multiple keys. For example, instead of writing WHERE id = 123 we write WHERE id in (123, 128).
We do this because our dataloader’s batching function receives a batch of multiple keys and passing those into a single DB query reduces hits to the DB.
This works great for loading multiple records by foreign key as well.
For example, if we query all users on a particular team, we can issue a single DB request and cache on the teamId foreign key.
Additionally, we can cache each of the users on their primary key userId, which means any subsequent user queries for any team member would result in a cache hit.
Recipe #2: Authentication, Nesting, and REST APIs
A dataloader is our first line of defense in getting rate limited by an external REST API. To achieve that, we first have to figure out how to authenticate with the external resource.
For this example, let’s assume the resource uses OAuth2. Calling an authentication endpoint with a refresh token provides us with an access token that typically works for 30-45 mins. It’d be wasteful (and slow) if each request first had to request a new access token, so how do we reuse access tokens across disparate requests?
Fresh Authentication
The answer is to cache the access token in our own local database and use a dataloader to keep it fresh. For example, here’s our entire dataloader that guarantees a fresh access token for Atlassian Jira:
Here we’re hitting our DB to find the existing access token. If that token is within a minute from being expired, we fetch a new token and save that to our DB. Finally, we return the token. Now that we have a valid access token, we can nest this dataloader inside others.
Nesting an Authentication Dataloader
Continuing with the Jira example, here is how we fetch multiple issues:
The first line of the batch function attempts to grab a fresh access token using the dataloader from before. In our use case, it’s not uncommon to fetch 10 or 20 issues in a given GraphQL request. By nesting the authentication dataloader inside the issues loader, we can guarantee that we only send at most one request to Atlassian for a new access token.
In this particular example, Atlassian doesn’t allow us to request multiple issues by key so we still have to send one network request per issue. However, the dataloader still saves us additional network requests because it guarantees that we’ll never ask Atlassian for the same issue twice.
It’s also worth noting that the entire dataloader is wrapped in a function that provides a dataloader dictionary. We’ll discuss this in Recipe #4.
Recipe #3: GraphQL Endpoints
The above example is pretty common because just about every external service offers a REST API. Notice that we glossed over the manager.getProject() function. Behind the scenes, that function adds the parameters to a URL, adds the proper headers, fetches the URL, and handles any errors.
Wrapping a REST service in GraphQL has its drawbacks though. For example, in Parabol we have a Sprint Poker meeting that rarely needs to fetch the Story Point Estimate field from Jira.
Herein lies the problem: Do we build our dataloader to ALWAYS fetch the Story Point Estimate field, even if we don’t need it? What if instead of just 1 extra field we sometimes need to fetch an additional 100 fields? Do we build a separate dataloader like jiraIssuePlusAllFields?
GraphQL solves this key problem by allowing us to explicitly state which fields we need. So how do we leverage that when we’re integrating with a developer-friendly service like GitHub that offers a GraphQL API?
The answer is to use a dataloader to batch together the requests, merge the GraphQL fragments into a single request, and send it off to the service.
For example, say one piece of the app wants the issue author & the other wants the issue content:
We can use dataloader’s batching functionality to merge these into a single query. Since they are both named “issue”, we’ll simply have to alias one of them so the resulting JSON won’t have a name conflict:
This pattern was so useful that we broke it into its own package and open sourced it.
To learn more, check out nest-graphql-endpoint.
Recipe #4: Dataloader Dictionaries
A single dataloader can only be used for one entity type, e.g. User, Team, or Task. It’s not uncommon for a GraphQL request to include hundreds of different types. For this reason, we create a dictionary of dataloaders.
In the most naive implementation, a dataloader dictionary would be a simple object where each key is the dataloader name and each value is its dataloader. This works perfectly well for small apps. However, this strategy doesn’t scale as the number of dataloaders increases. Recall that a dataloader should only be used for a single GraphQL request to avoid stale data. That means even the simplest GraphQL request would have to create a dictionary, including possibly hundreds of dataloaders, the majority of which will never get used.
In our case, each dictionary took ~50KB of memory. That’s a whole lot of garbage collection to run after each request!
We solved this problem with lazy instantiation. Our dataloader dictionary has a get method that accepts the name of the dataloader. The first time it is called, it creates the dataloader:
By using some TypeScript generics, we get the same type safety as a plain old JavaScript object without the extra burden on the CPU to create and destroy hundreds of datalaoders on each request.
Recipe #5: Dataloader Warehouses
Our app relies heavily on GraphQL subscriptions. For example, if a user creates a task, we share that event with their entire team in Parabol. GraphQL’s subscription model uses Data Transform Pipelines. So instead of sending subscribers the exact message that we sent to the person who triggered the mutation, we send them a custom tailored message based on their permissions and fields requested.
For example, if a user creates a private task, we might send team members the event that a task was created, but we wouldn’t share the private content. Since subscriptions are long-lived, they can’t use the dataloader’s cache functionality. That means when someone creates a task, they hit the database once and every other team member hits the database as well. That approach doesn’t scale!
To solve this problem, we share the dataloader dictionary with all the subscribers and thus reduce the complexity from O(n) to O(1).
To achieve this, each mutation checks out a new dataloader dictionary from the warehouse. When it publishes the results to subscribers, it includes the dictionary ID. Each subscriber can then fetch that dataloader dictionary by ID and reuse it. Doing so means all entities are already populated. But it will still go through the GraphQL resolvers, which is where we keep permissions.
Conclusion
GraphQL datalaoders have allowed us to reduce traffic to our data sources. This means the end user gets a faster response and our developers can focus on building new features instead of scaling the existing architecture.
To learn more, our entire production codebase is open source and available on GitHub. If you’d like to get paid to work with dataloaders, we’re hiring!





