Scaling GraphQL with Redis Consumer Groups

We’ve just hit over 200,000 users at Parabol. With all this extra traffic, we noticed response time latency starting to increase, which makes sense because until recently we only used a single NodeJS server!
While investigating, we realized the bottleneck wasn’t with our highly efficient custom uWebSockets server (we still only use 1 of those). Instead, the latency was coming from all the GraphQL requests.
We decided to scale our GraphQL server from 1 instance into a cluster. And we did it using Redis consumer groups.
Why use Redis Consumer Groups?
Redis released consumer groups in v5.0, back in October 2018. Despite being around for almost 4 years, they’re still relatively unpopular, which is a crime considering how elegant they are.
It’s our strong opinion that Redis consumer groups are THE best option for startups looking to scale their services.
As a company that works entirely in the open, we thought it would be a great opportunity to show how we use them at Parabol.
Alternatives to Redis Consumer Groups
Before settling on Redis consumer groups, we considered a few other alternatives, including Apache Kafka and BullMQ.
Specifically, we could go all in on streams and adopt Apache Kafka (or a hosted Kafkaesque service), or we could use a multi-purpose tool like BullMQ, which uses Redis pubsub, but still has a considerable amount of logic in Node.
Kafka had too many moving parts
Kafka’s two greatest features are message persistence and message ordering. And we don’t care about either of those. If a message gets lost, it’s not like a bank transfer only halfway completed. The worst case scenario is that a user will reload the page. Conveniently, because Redis is in-memory & doesn’t offer either of these guarantees, it’s also faster than Kafka, although at our scale this is just theoretical.
Ultimately, we opted against Kafka primarily because we wanted to reduce the number of moving parts our application requires. Many customers prefer on-premise hosting so including Kafka would increase our infrastructure complexity and cost.
BullMQ meant more code to maintain
Work queues like BullMQ are also fantastic, but include a non-trivial amount of extra code that we would have to maintain.
When adopting a new package, there’s always the possibility of finding edge cases, memory leaks, or general strange behavior. Some of our customers have very strict security protocols, so we try to limit our dependencies. Because BullMQ relies on Redis pub/sub and also offers additional functionality like retries, the throughput is increased by the extra messaging. We’re pretty confident this wouldn’t become a bottleneck, but it’s worth mentioning.
Redis offered us the same result with its built-in streams API, so we opted for the simpler solution.
Basic Architecture with Redis Consumer Groups
Our infrastructure should be no more complicated than ordering a cup of coffee:
- You walk up to the counter and place your order
- The order gets sent to the back, where a barista makes it
- The barista gives your coffee to the cashier, who calls out the name on the cup and off you go
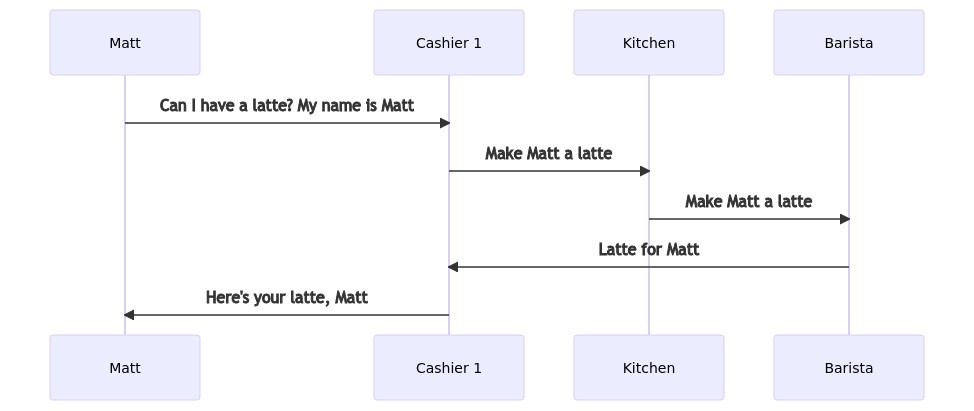
The novel concept in this case is that the cashier doesn’t pick the barista. The order gets printed on a ticket and the next barista in line gets assigned to make the coffee. When it’s complete, the barista gives it to the cashier who initiated the request.
Similarly, our socket server doesn’t care which GraphQL executor performs the work, but the work has to get back to the requesting server.
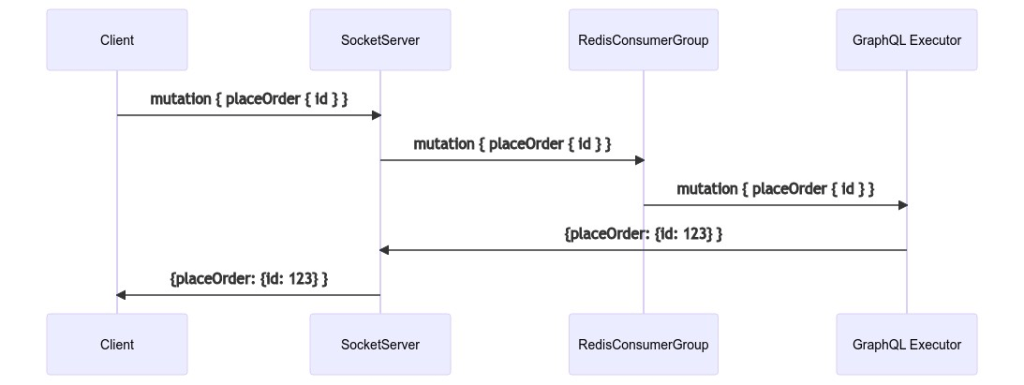
Basic Typescript Implementation in NodeJS
Consumer Groups power everything in our application – from reading data when the page first loads to actions like starting a new meeting.
Previously, our only socket server connected to our only GraphQL Executor via a Redis Pub/Sub. Using the coffee shop analogy, we only had one barista! With a cluster of GraphQL Executors, using a Pub/Sub wouldn’t work because the publisher would have to decide which consumer should get the message.
That means it would have to be aware of how many executors there are, which ones are currently running, and the current load for each one. Those are exactly the problems that a consumer group solves. You create a consumer group, then each consumer tells the group when it’s ready to receive another message.
try {
await redis.xgroup(
'CREATE',
'gqlStream',
‘gqlGroup’,
'$',
'MKSTREAM'
)
} catch (e) {
// stream already created by another consumer
}Above, we’re creating a consumer group and a stream all in a single command. In more advanced applications, multiple consumer groups could listen to the same stream, but we keep it simple: one stream has one group.
const response = await this.redis.xreadgroup(
'GROUP',
‘gqlGroup’,
// uniquely identify this particular GraphQL Executor
consumerId,
'COUNT',
1,
// block the redis connection indefinitely until a result is returned
'BLOCK',
0,
// no pending entries list (lost messages are not retried)
'NOACK',
'STREAMS',
'gqlStream',
// listen for messages never delivered to other consumers so far
'>'
)The next command is pretty gnarly. It’s a blocking command, which means the promise doesn’t resolve until a new message is received. For that reason, we stick it in an async iterator so when a message is received, the message is sent to GraphQL and this blocking function is immediately called again, signaling to Redis that it is ready for another message.
We also pass in the NOACK flag. By default, when Redis sends a job to a consumer, it also stores that job in a Pending Entries List (PEL) and it stays there until the consumer sends an ACK to Redis (usually when the job is complete). This is useful for important jobs like transactions. If the job stalls out or the consumer crashes before an ACK is sent, another consumer can pluck the job from the PEL.
For the use case of a GraphQL web app, a PEL is not necessary. A client expects a response within a couple seconds. Waiting for a job to timeout and then retrying it on another consumer would take too long. Instead, we can tell the user there was a server error and give them the option to reload. It’s a simple solution that avoids each consumer checking the PEL for abandoned jobs.
With the 2 calls above in place, all that’s left to do is add messages to the stream.
const publisher = new Redis(REDIS_URL)
publisher.xadd(‘gqlStream’, 'MAXLEN', '~', 1000, '*', 'msg', message)The xadd method pushes the request to the end of the stream and makes sure the stream is capped to about 1,000 messages. I say “about” because by using `~` Redis will wait until it can delete an entire macronode of messages. This may exceed 1,000 by a couple dozen, but results in a more efficient operation. Since there’s no PEL, the consumers can digest messages just as fast as the producers can send them, so 1,000 messages is more than plenty.
Notice that I call the connection above “publisher”. That’s because we can reuse this connection as a pub/sub publisher, too.
Redis Pub/Subs for GraphQL Subscriptions
Once a consumer finishes resolving the GraphQL request, it has to get that response back to the server that requested it.
To do this, we use Redis Pub/Sub. Before a message gets posted to the consumer group, a serverId gets appended to the message. Each producer is subscribed to a Redis Pub/Sub channel with that same serverId. That way, once the consumer finishes, it can publish the response directly to that serverId’s channel.
// Producer setup
const subscriber = new Redis(REDIS_URL)
const serverId = '42'
subscriber.subscribe(serverId)
subscriber.on('message', () => {/* send to client */})
// Producer message handling
const message = {data, serverId}
publish.xadd('gqlStream', 'MAXLEN', '~', 1000, '*', 'msg', message)
// Consumer message handling (via xreadgroup)
const {data, serverId} = message
const response = await graphql(data)
publisher.publish(serverId, response)Subscriptions Architecture: Source Streams & Response Streams
Now that we have a basic request/response architecture in place, we need to handle subscriptions. Expanding upon the coffee analogy, imagine a scenario where one customer was interested in the actions of another.
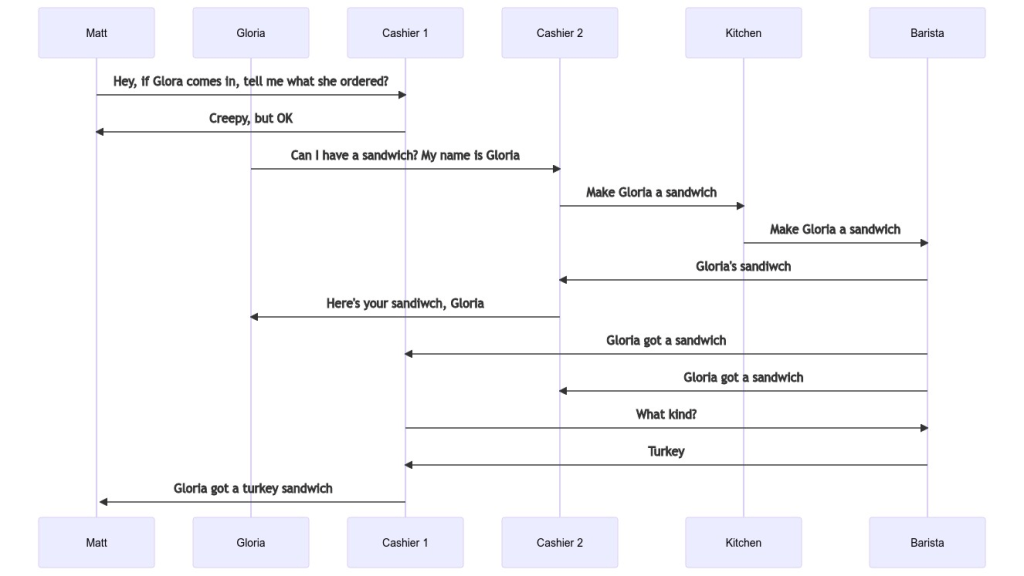
The novel part here is that when the barista hands the drink to Gloria’s cashier, they also announce that Gloria ordered something. The barista doesn’t care who is listening, they just shout it out. That leaves it up to Matt’s cashier to ask for more details about the order.
That initial announcement is what GraphQL calls a SourceStream. The followup message with the extra details is the ResponseStream.
We’ve taken this analogy as far as it can go, let’s see how it looks in our application.
Subscription Implementation
When the GraphQL Executor finishes the query, it publishes the bare minimum details to a particular channel. There might be 0 or 100 socket servers listening to a single channel. Each socket server might be listening on behalf of 1 or 1000 users, each interested in different attributes about the event. Some users might care about the size of the sandwich, others may care about the content, the bread, or the price.
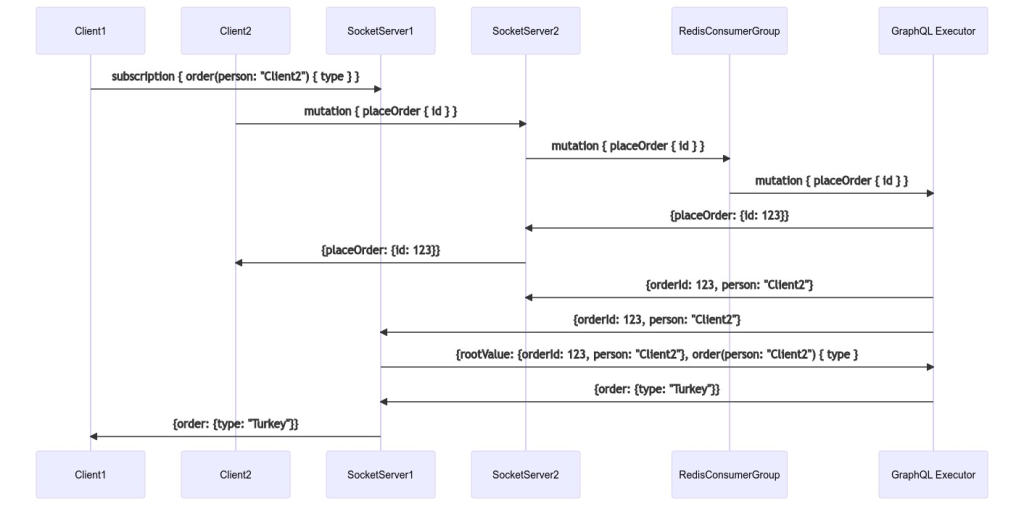
The idea that a single event can result in a custom response for each user is what GraphQL calls a data transform pipeline. A single event publishes a very small amount of data to the SourceStream, e.g. {userId, orderId}. When the SocketServer receives this event, it pairs it with the subscriber’s GraphQL query and makes a new GraphQL request, resulting in a ResponseStream event.
If this extra back and forth communication seems inefficient, it is! It’d be simpler to have a single GraphQL service that handled both queries and subscriptions.
However, there are two good reasons to break them up:
- Scaling stateless services is easy. Scaling services with state is hard (e.g. a WebSocket, GraphQL subscription, Video call, etc.)..
- If a team’s users are split across multiple servers, they can’t share the same in-memory, per-request cache we call a dataloader.
Stateful services require knowing about the connectivity status of each user, usually implying some type of ping. They need to be sticky to ensure a user gets the same server for each request. They’re susceptible to memory leaks because data is kept on them.
The second reason is nuanced to our use case. For each query or mutation, an in-memory dataloader is instantiated and populated during the resolution of that operation. For example, if a mutation queries user123, the first query goes out to our database. All subsequent queries use that cached value. To learn more about dataloaders, you can read our Dataloader Cookbook.
We give that dataloader a five second time-to-live, which is plenty of time for all the subscribers to reuse it. This reuse means that transforming a SourceStream event to a ResponseStream event generally takes a couple milliseconds. The expensive queries going out to a database or external API have already been cached!
The gotcha is that every subscriber needs to issue this request to the executor that performed the initial operation. If another executor resolved the request, it wouldn’t be able to reuse the dataloader, which would cause a little extra latency.
Therein lies the downfall of having a GraphQL service handling both subscriptions and queries. If a team of 10 is split evenly across two servers, only half could reuse the dataloader.
There are workarounds: you could serialize the dataloder’s cache to Redis and other services could load it from there, but compared to a SourceStream event, that’s a much bigger payload, which means extra throughput, CPU cycles, and latency.
Conclusion
Our current architecture uses Redis Consumer Groups to balance the workload across a cluster of consumers we call stateless GraphQL Executors. Replies are sent using Redis PubSub. Subscriptions and WebSockets are kept on stateful servers that scale independently.
This work has reduced our latency and has opened the door to our graceful migration to Kubernetes for our cloud deployment, which we’ll write about soon.





