
This week, we shipped a new version of Parabol to production that enhances its performance with a new server-side cache.
Warning! Nerdy post ahead!
Soon, we’ll have new members on the product team. Before they start we wanted to get some basic patterns put into place they can build on and maintain our application performance. One of these patterns is caching: which provides the ability for our server to get information from local memory, or fast data storage, without having to go and ask the relatively slower database. For our users, this keeps interactions feeling snappy.
Details please…
Before this update, almost every data request required looking up the current user in the database. For each request from the client to the server, we’d avoid repeat lookups by using the GraphQL DataLoader. However, each new request would hit the database again.
With the changes we shipped in v5.11.0, we now implement a 3-stage cache:
- Stage 1 is a local cache (Node process), which stores parsed JSON
- Stage 2 is a remote cache (Redis), which stores the document in serialized JSON
- Stage 3 is the DB itself (RethinkDB)
Stage 1 also batches read/write requests to a single microtask to reduce latency. Stage 1 runs a garbage collector every hour to remove docs that haven’t been used in 1 hour.
Stage 2 uses Redis’s built-in TTL to expire documents after 3 hours. Stage 2 gets the missing items & looks them up in Redis. If not found, it queries Stage 3, caches the result, and returns.
Stage 3 Batches all missing records by table and sends a single query to RethinkDB.
On write, Stage 1 updates the cached value if found, calls Stage 2, then returns when Stage 2 finishes. Stage 2 queries the current value from Redis. If found, updates the value in Redis and calls Stage 3. Stage 3 batches all updates and sends a single query to RethinkDB.
To see the source in detail, see this GitHub pull request.
Metrics
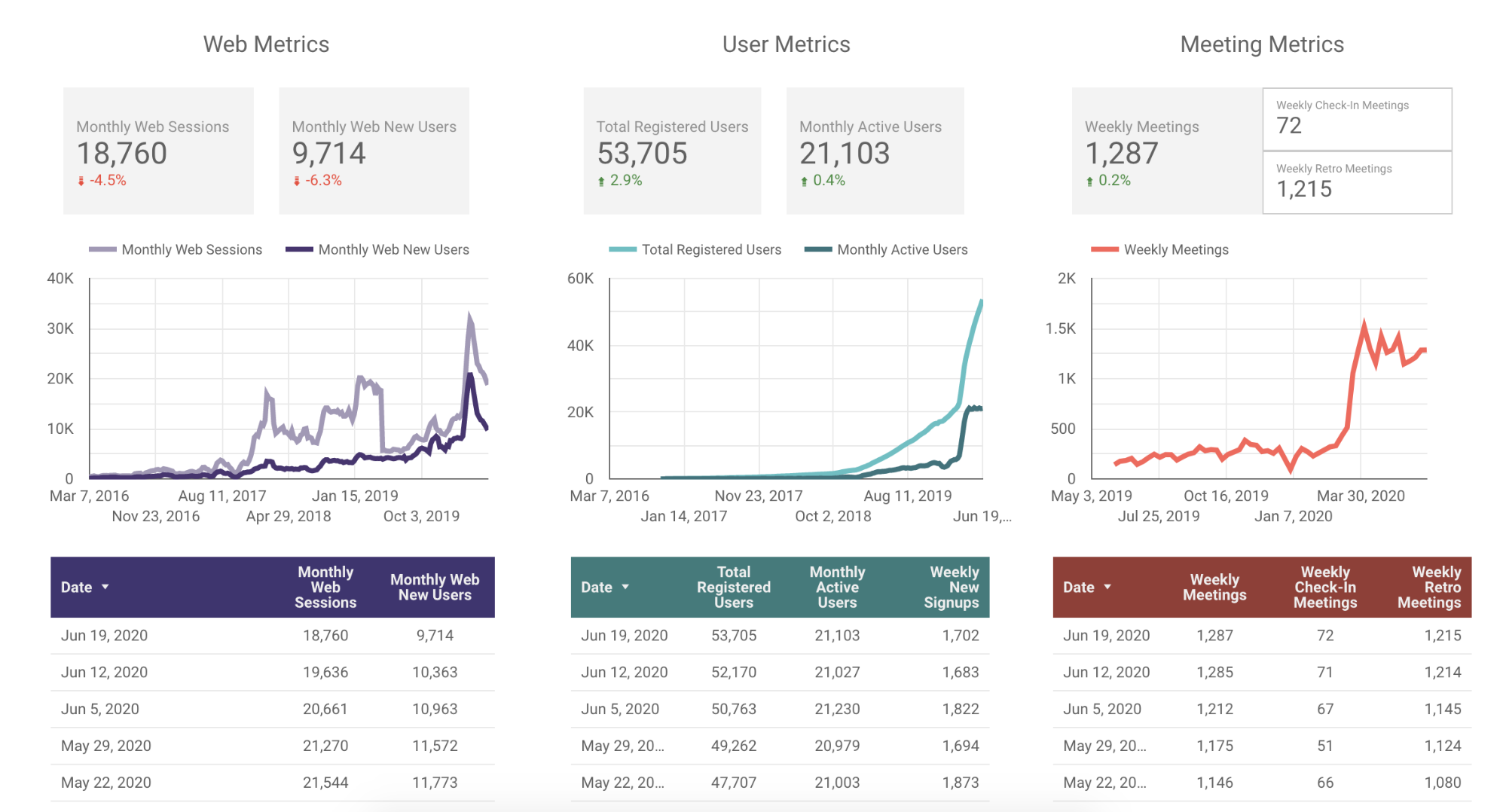
Search traffic was down 6% and referral traffic down 17% this week (not shown in tables above), while other traffic sources were all up. Decreasing traffic has caused our priorities to shift an effort to get things increasing again. User metrics were all up slightly this week as we continue to see gains from current users inviting more users…
This week we…
…launched new ads on Google and Facebook. As we shift out of the period where many companies are starting to go remote and into a new baseline, we’re experimenting with ads to supplement our organic top-of-funnel growth. We’re excited to kick-off this work with EmberTribe!
…published a post on why meetings are great. Meetings have been getting a bad rep as folks experience more and more bad meetings. We think it’s not the meeting format’s fault – it’s because most meetings are bad.
…scheduled 10+ user interviews next week to assess our Sprint Poker meeting format. We’ll be talking to folks who already use Parabol and those who run planning meetings on other tools to refine what we’re building.
…delivered a privately-hosted instance of Parabol including SSO integration for one of the top 10 largest stock exchanges in the world.
Next week we’ll…
…wrap up sprint 58. We’re implementing the ability for folks to export comments from retro and check-in meetings, designing a new sub-system for sharing meeting templates, and polishing off a big design cycle.
Have feedback? See something that you like or something you think could be better? Leave a public response here, or write to us.